Developed an ensemble machine learning approach to predict stress values from material interface properties and strain input data. The project focused on capturing non-linear stress-strain relationships through a sophisticated model selection and averaging methodology.
| Model | Mean R² | Validation R² | Validation RMSE | Runtime |
|---|---|---|---|---|
| Random Forest | 0.7139 ±0.0122 | 0.7157 | 55.9973 | 10.83 min |
| XGBoost | 0.7616 ±0.0058 | 0.7651 | 50.9077 | 0.24 min |
| Combined | n/a | 0.7638 | 51.0468 | n/a |
Implemented k-fold cross-validation (k=5) to balance computational efficiency with statistical reliability. The combined model architecture averages predictions from both RF and XGB models, effectively:
Developed a sophisticated cryptocurrency price forecasting system combining historical market data with Twitter sentiment analysis. The project achieved a high R² value of 0.7008 using Random Forest, demonstrating the effectiveness of sentiment analysis in predicting short-term price movements.
The Bitcoin value is infamously volatile and many models struggle to predict its behavior. Traditional models rely on historical prices alone, but our goal is to build a smarter forecasting model that integrates both crowd sentiment from Twitter data and technical indicators from previous prices, using more features to better predict Bitcoin's future value.
Bitcoin and other cryptocurrencies are notoriously volatile. Emotions like fear and greed drive massive price swings, often reflected on platforms like Twitter before the market reacts. By analyzing both market behavior and social sentiment, we aim to:
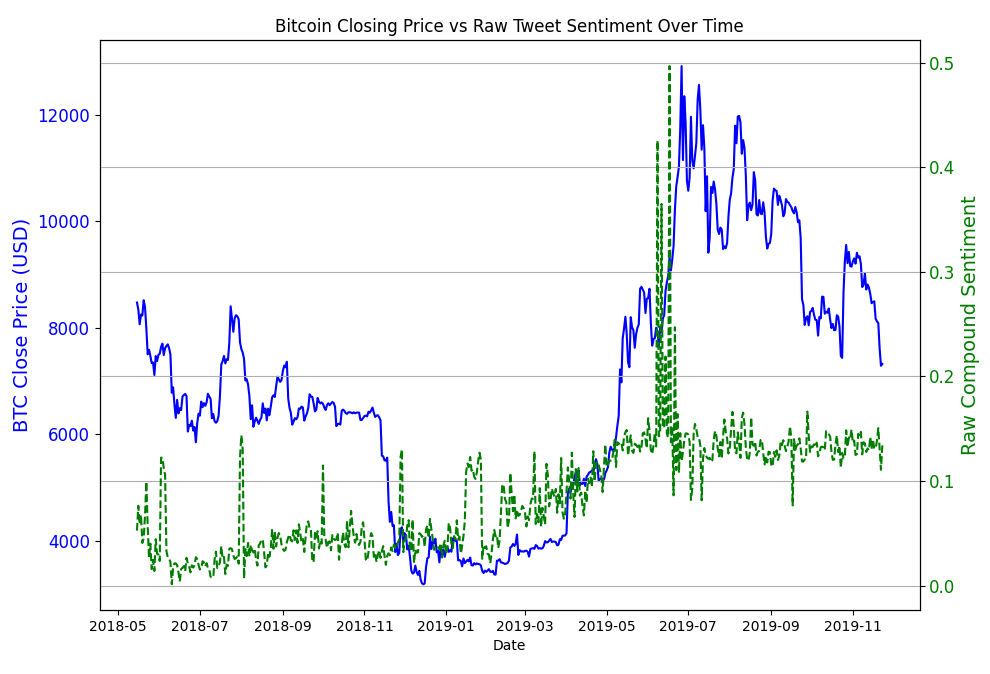
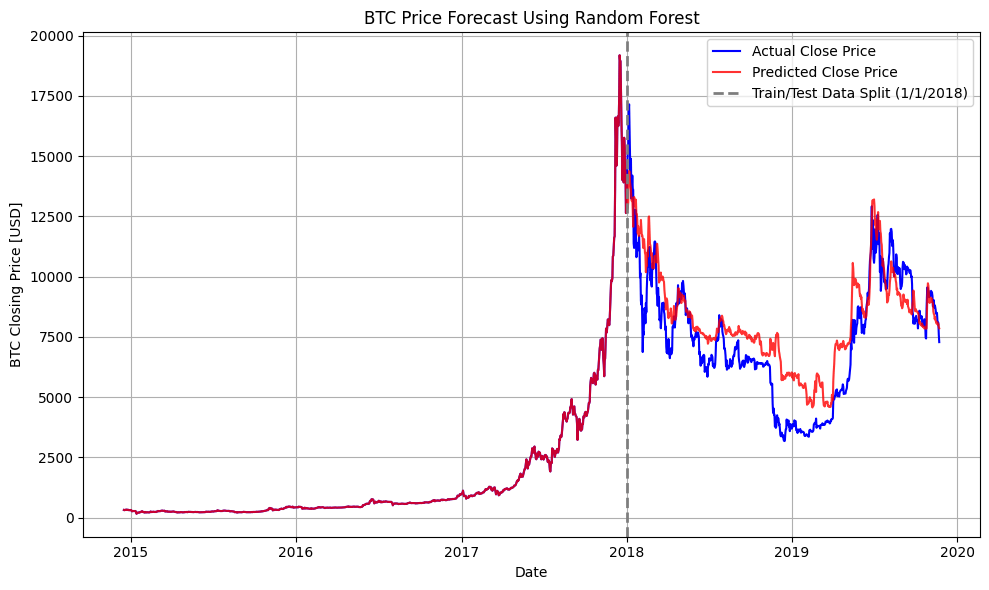
BTC price and sentiment correlation analysis, and Random Forest model price predictions
| Model | R² | MSE |
|---|---|---|
| Random Forest | 0.7008 | 2,021,834.19 |
| XGBoost | 0.6946 | 2,063,875.95 |
| LSTM | 0.6138 | 2,692,072.46 |
While all three models were evaluated, Random Forest was chosen as the final model for several key reasons. The model comparison reveals important insights about each approach's strengths and limitations:
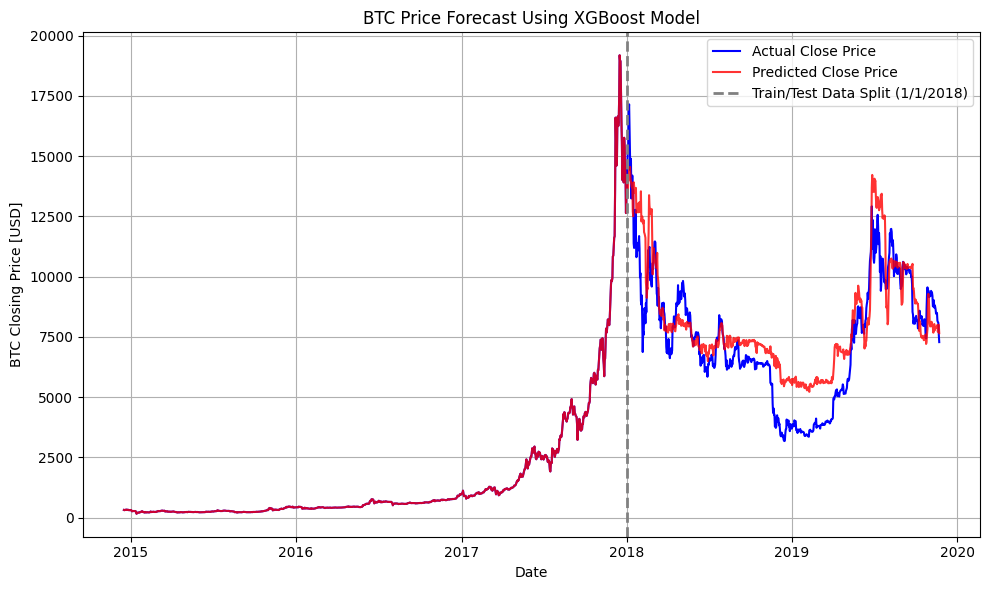
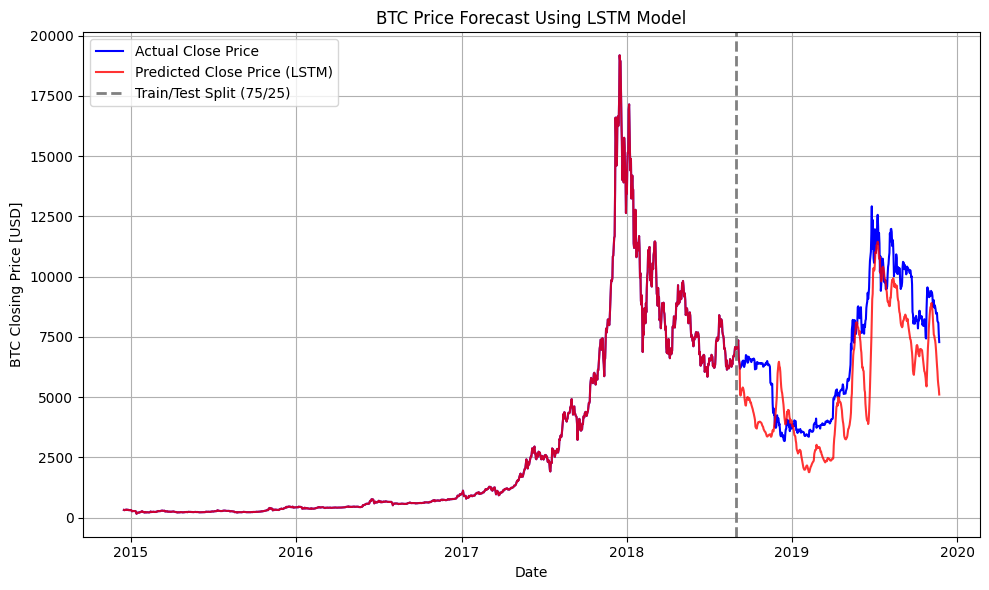
XGBoost showed similar performance but was more sensitive to market volatility; LSTM struggled with the hybrid nature of our feature set
Our chosen model achieved a R² score of 0.7008 on the post-2018 test data set. The predicted vs. actual BTC prices show that the model tracks short-term trends and direction well. Larger deviations occur during high volatility, suggesting that further robustness techniques (e.g., uncertainty quantification) could be valuable.
TL;DR – Developed ensemble ML models for mechanical analysis achieving 0.76 R² and implemented sentiment-based Bitcoin price prediction with 0.70 R² accuracy, demonstrating advanced machine learning applications in engineering and finance.